
Imagine you are tasked to write 417,823 lines of code in 6 different languages. What if there was a way to slash that development effort significantly with just a fraction of the effort? Introducing code generation, where a few high-level instructions can do the work for you. In this blog post, we'll dive into the superpower of code generation, uncovering its presence from early programming to modern-day AI assistants.
Code generation is ubiquitous in software engineering, it exists in literally every part of the stack from programming languages to the websites we browse. So why is code generation everywhere? Because code generation empowers developers. By automating tasks and creating simpler abstractions, code generation makes developers more productive and less error-prone.
At C3.ai, I worked on a tool that leverages code generation to build enterprise AI applications. At the same time, I became deeply immersed in the art of code generation by building the tooling myself. Since then, I enjoy learning about code-generation technologies across the entire software stack from programming languages to AI assistants.
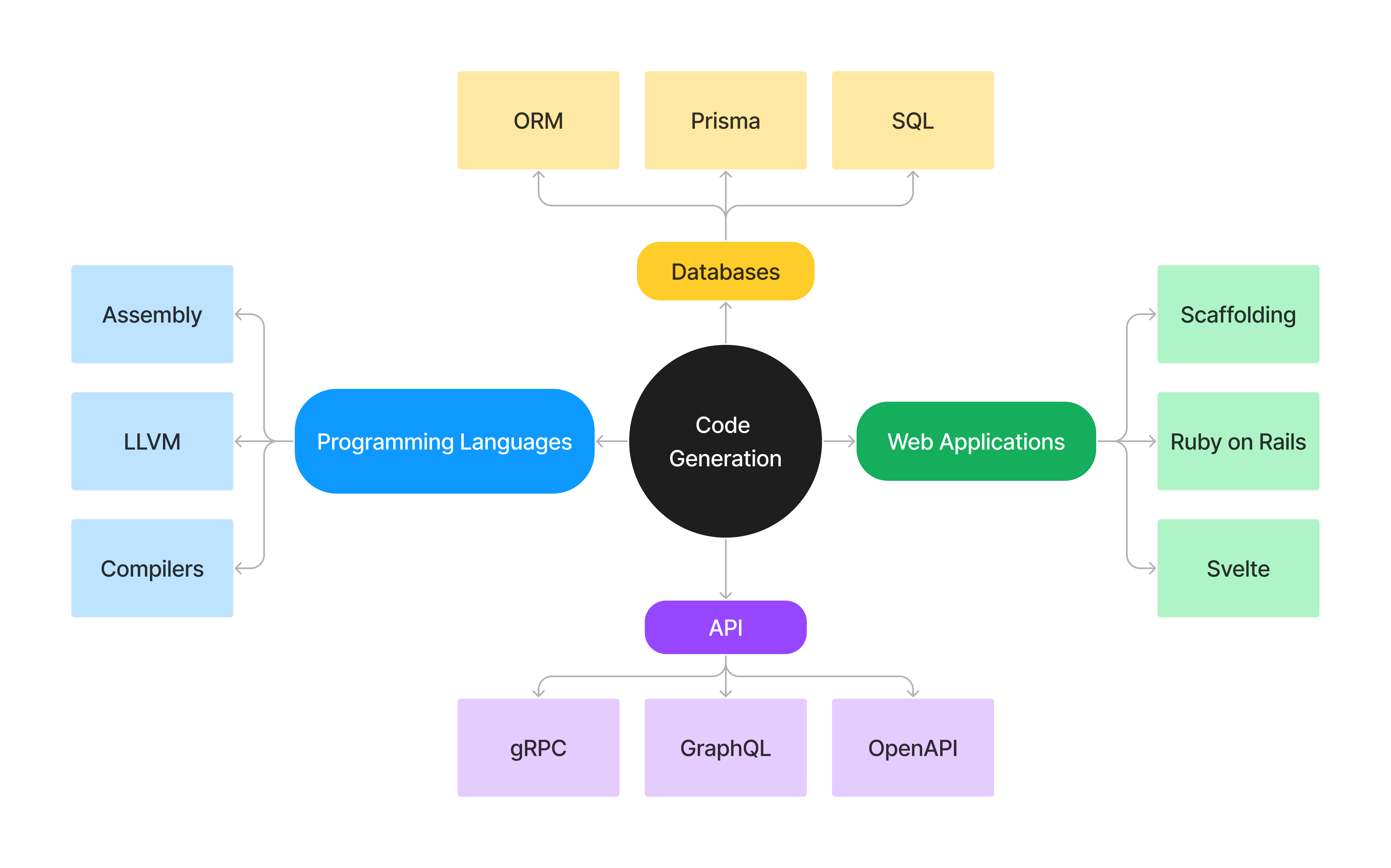
Why Generate Code?
Code generation is the automated process of producing code from a high-level representation. Code generation tools parse input data to produce target code in programming languages. The most notable high-level representation is programming languages.

When the first electrical computers were created, physical switches were used to program computers. Physical switches are extremely error-prone and time-consuming to operate. So with the invention of the CPU and instruction sets, the first software form of a programming language was invented, assembly.
Assembly is a linear series of instructions for the computer to execute. Assembly is used to generate the lowest level of instructions for computers, machine code.
The classic amusement park simulator RollerCoaster Tycoon was written using assembly.
But still, assembly code is tedious and error-prone to write so programming languages that generate to assembly were invented. Here is the same "Hello, World!" program written in popular programming languages.
After comparing the "Hello, World!" program in assembly to the ones written in higher-level programming languages, it's clear that code generation empowers developers to be 100x more productive. If you think about it, software engineering is simply operating code generators to produce performant machine code 🤯.
Compilers are the code generators that power programming languages. Compilers turn a source language into a target language. In practice, most computer languages target assembly code in instruction sets such as x86 and ARM, but others like Java target their own instruction set. Some programming languages compile to other programming languages such as TypeScript to JavaScript.
Compilers themselves are typically written in the programming language itself. This concept is called bootstrapping.
Nowadays, compilers are so advanced that there is rarely a reason to write pure assembly code. In most cases, writing applications in a programming language leads to faster programs than writing programs in assembly due to amazing compiler infrastructures like GCC and LLVM.
Watch this fascinating video about branchless programming. The video covers an example of why in some cases you need to know exactly how programming languages work to beat the compiler.
Database Code Generation
One code-generation pattern that has found a lot of traction is in Object-Relational Mapping (ORM).

For context, databases define a domain-specific language that allows them to build a generic execution engine for querying data. Databases can then optimize the execution engine while still providing a flexible interface for querying data. Today the most common type of query language for databases is SQL (aka Structured query language). But SQL is tedious to read and write, especially if you have to write many read or write operations to a database in a single codebase.
Enter Prisma, an extremely popular library with 33k stars on GitHub for building applications that interact with a database like PostgreSQL or MongoDB. Prisma is an ORM that leverages code generation to allow developers to easily use databases by generating database migration queries in SQL and type-safe clients to interact with the database.
Take for example a TypeScript function that makes two simple queries. With Prisma, we can convert plain-text SQL statements to typed function calls and delete over 50% of the code.

Prisma's superior developer experience allows developers to move fast without breaking things. Unsurprisingly, Prisma has found itself as a fan favorite amongst Node.js developers, quickly beating out existing ORMs.
Other modern ORMs like EdgeDB recognize the benefits of code generation in delivering a great developer experience and are actively integrating code generation capabilities into their ORM.

By taking database interactions to a higher level, Prisma and EdgeDB hope to build an intelligent layer over SQL that can produce queries that would take a human hours or even days to craft. But in general, ORMs like Prisma and EdgeDB leverage code generation to fulfill an ongoing pursuit of more efficient, developer-friendly, and maintainable solutions for database interactions in modern software development.
Web Application Code Generation
Web application technologies have existed since the dawn of Web 2.0. In parallel, frameworks for building web applications have found traction amongst developers. This is because web frameworks abstract or automate the tedious code needed to build full-stack applications.
Ruby on Rails, which has been used to build giant tech companies such as Shopify and GitHub, is famous for tooling that automates the tedious work when building a full-stack application. Rails does this by providing a CLI for generating commonly used code while developing.
For example, if you wanted to create a blog as a Rails application, you would simply run:
The CLI will then set up all the boilerplate code to start developing your web
application in Rails under the blog/ folder. The rails CLI also offers code generation for tests,
database migrations, models, and more. Code generation with Rails saves
developers hours of setup and maintenance work. Teams of developers also move
faster with code generation by enforcing best practices within the generators
themselves.
RedwoodJS, a full-stack framework built on top of modern web technologies like GraphQL, TypeScript, and Prisma, leverages code generation to generate UI components in the form of cells.
Django, the Python project powering products like Instagram, leverages code generation to generate database migrations.

Another use case for code generation appears in the latest front-end framework for browsers, Svelte. Svelte disrupts front-end frameworks such as React or Vue by introducing a compiler that drastically improves the developer experience when building complex front-end applications.

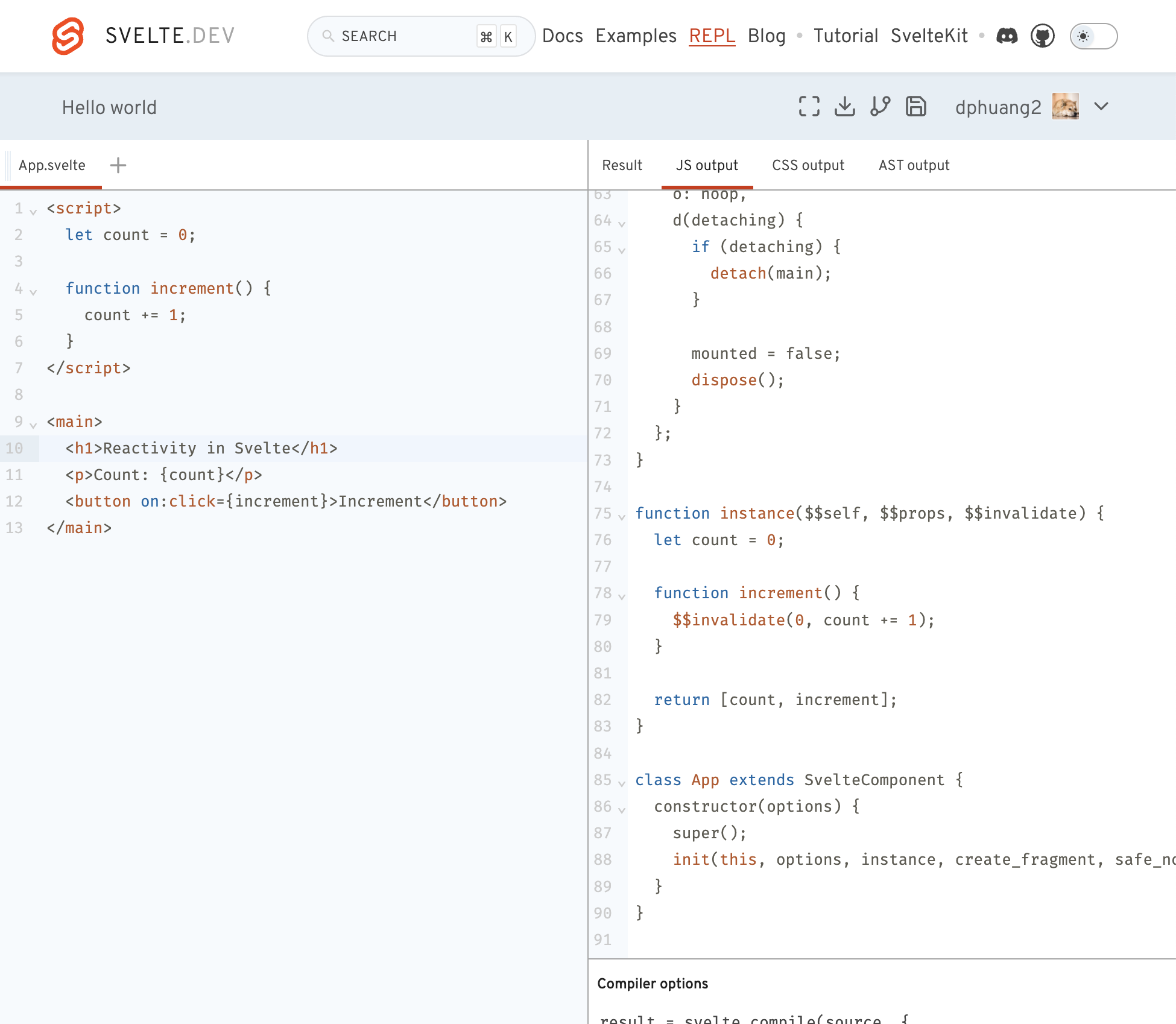
The main benefits of the Svelte compiler are reduced bundle sizes, performant front-end code, and improved developer experience. For example, here is a simple web page written in Svelte that displays how many times a button was clicked.
The same web page written in React has additional import statements and boilerplate code from setting up a functional component and state.
The simplicity of Svelte is made possible by its compiler. By adding a code generation layer at build time, Svelte can provide a clean interface for building front ends while maintaining reactivity and state management functionality.
Web API Code Generation
Adjacent to web applications are Web APIs, which can be really complex. But code generation drastically simplifies API integrations by generating boilerplate code and client libraries. Network protocols such as GraphQL, gRPC, and OpenAPI not only streamline API development but also leverage code generation to create server-side scaffolding and client-side SDKs, enhancing API consistency and reducing complexity.
GraphQL has found a lot of traction when building front-end applications due to
its self-documenting workflow and flexibility for front-ends to query for only
necessary data. Developers can generate clients for a GraphQL API to remove any
boilerplate code and enforce type safety. For example given the simple GraphQL
schema for a User model and a getUser query.
We can leverage
graphql-code-generator
to generate type-safe query hooks in React. Notice that we simply import the
query and pass in the necessary variable, userId. No need to manually
construct an HTTP request, serialize a request body or deserialize a response
body.
_30import React from 'react';_30import { useGetUserQuery } from '../generated/graphql';_30_30const UserComponent = ({ userId }) => {_30 const { loading, error, data } = useGetUserQuery({ variables: { userId } });_30_30 if (loading) {_30 return <div>Loading...</div>;_30 }_30_30 if (error) {_30 return <div>Error: {error.message}</div>;_30 }_30_30 const user = data?.getUser;_30_30 return (_30 <div>_30 <h2>User Information</h2>_30 {user && (_30 <div>_30 <p>Name: {user.name}</p>_30 <p>Email: {user.email}</p>_30 </div>_30 )}_30 </div>_30 );_30};_30_30export default UserComponent;
For gRPC, communication happens between two backend systems so code is
generated for a server-side language such as Python. Using the same User
example in GraphQL, the .proto file for gRPC is the following.
Using grpcio-tools to generate a
client in Python we can write the following code to communicate with the
UserService.
In OpenAPI, communication is typically between a third-party developer and a
public API such as Stripe. Using the same User example
again we can define the following OpenAPI.
And use openapi-generator to generate a publishable client SDK in Python.
In all three examples, generated client SDKs remove unnecessary code to construct an HTTP request or handle serialization and deserialization. Furthermore, any unexpected data errors are caught during development time. As the number of operations and data models grows, the same code generation tooling can be used to ensure consistency throughout API integrations.
When Not To Use Code Generation?
Like everything in engineering, there are tradeoffs. Even though code generation is powerful, generating code adds a layer of complexity that is not always warranted. In some cases, it does not make sense to generate code as it slows the development process or the same effect can be achieved more simply. Compilers are not simple; the LLVM has over 400,000 commits for a good reason. Compilers have to treat code as data which leads to wildly complex ASTs and data flow analysis.
An example of when code generation should not be used is when building a data validation library for TypeScript or Python. You could theoretically generate data validation code from a standard specification such as JSON Schema. But languages like TypeScript and Python already come prepared with the typing functionality. Instead, we should re-use the typing functionality to create our data validation library. Popular examples of non-code-generation-based data validation libraries include zod for TypeScript and pydantic for Python. No compilation step is necessary which means they can be imported at any time and used in any runtime.
But when process boundaries are crossed such as HTTP APIs, data validation is not possible to achieve without code generation; hence the use of code generation in network protocols like GraphQL, gRPC, and OpenAPI.
AI Assistants
The latest form of code generation looks completely different than previous generations. Instead of domain-specific toolings like how ORMs generate SQL, AI assistants define a whole new input and output model. In particular, products such as CodePilot and Tabnine live inside of a developer's IDE, generating contextual code from the currently open files.
What do I mean by contextual code? This time, instead of providing a standard input format such as a programming language or API specification, the input format is simply the surrounding code in the open files. A suggested completion is predicted based on the context and offered as a tab-completion in the IDE. Since LLMs are probability-based models, its usefulness revolves entirely around prediction accuracy. A probability model works out great in IDEs because the generated code can easily be assessed by a human and there is virtually no risk when the suggestion is wrong.
The Cons of AI Assistants
As a Copilot power user, I can attest to its value today. But I can also attest to how Copilot introduces unwanted new complexity. But don't just take it from me, Microsoft even published a video guide on "Prompting with Copilot", teaching developers how to wrangle the complexity of prompting the AI while using Copilot. One tip from the video is to write an explanatory comment at the top of a file to give Copilot more context. For example, you could write the following comment at the top of a Python file.
Since everything is probability-based, providing enough context for the AI is crucial to improve its accuracy. But sometimes prompt engineering can take more time and effort than simply writing the intended code. And it doesn't help that AI is a black box, making experimentation a dark art.
When lots of context is required, which is often the case in larger codebases, the accuracy of the AI drops which can then lead to misleading or incorrect suggestions. Magic, a company building a software engineer inside your computer, recognizes this limitation and is on a mission to solve it.

My Thoughts on AI
Over time, we have engineered ourselves into higher and higher levels of abstraction to build performant software. Mojo, a new programming language for writing performant low-level code in plain Python, is an interesting and recent example.
From low-level assembly to AI assistants, compilers and code generation has proven to be a major productivity multiplier for software engineers. And with the most recent advancements in AI, we find ourselves asking, "Is natural language the final form of programming?". If a rules-based engine can be outperformed by LLMs, why spend thousands of engineering hours building one?
I believe completion-based assistants have a strong fit in the software development lifecycle, but LLMs just don't cut it when you need 100% accuracy, which is a common requirement in software engineering. But that doesn't stop some companies from nobly going all-in on AI-based code generation for problems. But from prompt wrestling experience with GitHub Copilot, which arguably probably has the most refined UX and traction amongst developers, I only see developers leveraging AI code generation in problem spaces where inaccuracy is acceptable. That being said, I am I would happily delete our entire codebase if AI can adequately solve the SDK generation problem.
Looking Into the Future
Code generation is a testament to the remarkable power of automation in software. From its early days in assembly language to the modern AI assistants, code generation has continuously evolved, unlocking new levels of productivity and efficiency for developers.
As we move forward, code generation will continue to be a vital tool, aiding developers in their pursuit of faster, more maintainable, and error-free software solutions. Embracing the right balance between automation and human expertise will be crucial in harnessing the full potential of code generation while acknowledging its limitations.
Are you leveraging code generation? What exciting advancements will the next generation of code generation bring? Will AI assistants revolutionize software engineering?